大規模言語モデルによるルーブリックに基づく能力評価
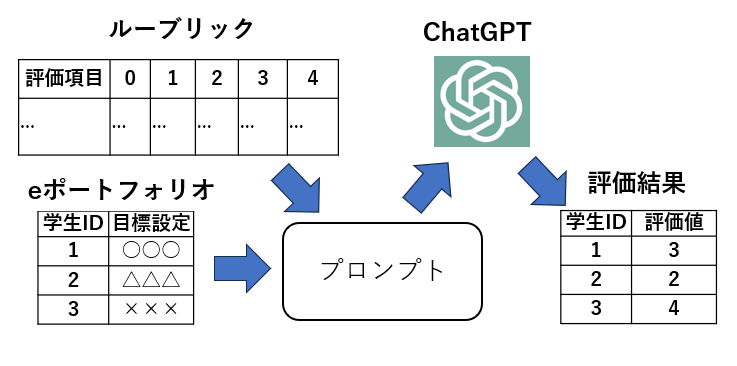
近年の高等教育機関では、主体性や課題解決力といったテストでは測ることのできない能力(非認知能力)が重視されています。しかし、非認知能力の評価を行うには、教員が学生の学習成果物や振り返りのデータ(eポートフォリオ)を個々に確認するため、教員の負担が大きいという問題があります。
これに対して、ChatGPTに代表されるLLM (Large Language Models) の発展が近年は顕著で、教育現場への有効な活用が期待されています。
そこで本研究では、ChatGPTを活用し、学生の主体性や課題解決力を教師の代替として評価する自動評価モデルを構築し、そのモデルの評価を行います。これにより、ChatGPTが教員に代わり能力評価が可能であるか検証しています。
これまでに、教員による評価基準(ルーブリック)の情報をChatGPTに与えることで、教員による評価とChatGPTによる評価には相関があることを確認しています。 現在は、ChatGPTへの指示文であるプロンプトの工夫(プロンプトエンジニアリング)により、ChatGPTの評価基準を教員の評価基準に揃えるという点で検証を進めています。