学生のレポート推敲のための話しことば検出システムについての研究
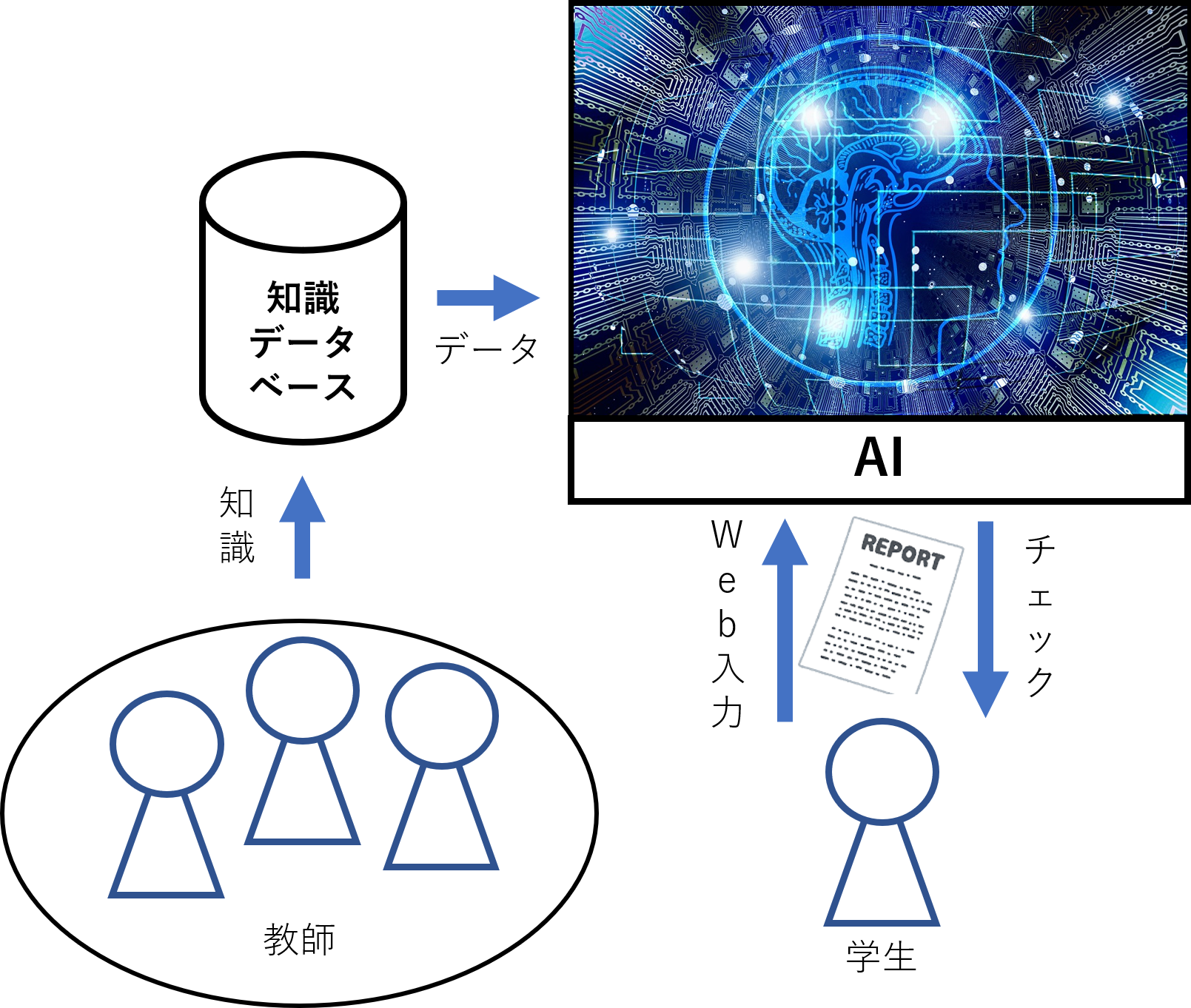
現在,多くの大学では、1年生でレポートの書き方など文章作法に関する授業が行われています。そこでは,適切な文章を書く力が求められています。しかし、実際には適切な文章を書く力が足りず、「あんまり」や「~てしまう」といった話しことばを含む文章が見受けられます。そこで本研究では、学生が「文章を書く、見直す、修正する」という文章作成の一連の流れの習慣づけをねらった、適切な文章を書く力を育成するためのWebシステムの開発を行っています。
本研究では、知識データベースというレポート指導を行う大学教員の話しことばに対する判断基準のデータベースを話しことばの検出に用いています。このデータベースには、例として「水道の水が飲めるのは日本では当たり前のことである。」という話しことばが入っている文章が記されています。この文章に対して「水道の水が飲めるのは日本では自明のことである。」という修正例の文章と、「または、当然と変えても良い」という解説が記されています。このように間違っている例文、修正する際の例文、その話しことばについての解説などの話しことばごとのデータが集められたデータベースになっています。この知識データベースをAIに学習させることにより文章を理解させ、自動的に話しことばを検出することができます。これは自然言語処理と呼ばれるAI手法の一つです。また、話しことばはデータベースにある、教員による知識ベースの判断以外に、話しことばか否かが不明瞭なものがあります。こうした曖昧な表現をAIに学習させることで、文章自体をAIが判断して、自動的に校正を行えるかの検証を行っています。 本研究ではAI的手法を活用して、卒業した学生のICT上の様々なデータから中途退学者傾向を始めとする学生の特徴を解析することを目標として研究を進めます。中途退学とは学生が途中で成績が良くないなどの理由で退学をしてしまうことです。学生の特徴を解析することで似たような学生が悪い傾向になりそうな場合に自動的に教員にメールを送信することで、教員から適切なアドバイスを送ることができます。
今後はいくつかの大学の協力のもと、様々な分野の文章のデータを収集することで、このシステムの改善と改良を目指しています。